Unified Lambda Architecture (Realtime DB + DW + OLAP)
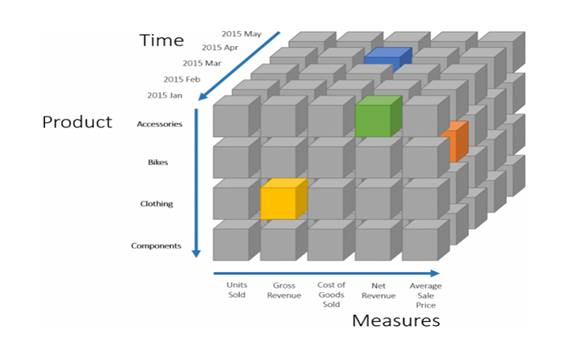
Blue → 2017 Apr + “Cost of Goods Sold” + Accessories
Yellow → Clothing + “Gross Revenue” + 2016 Jan
If we want 2015 Units sold for Accessories → sum up corresponding 5 coordinates. Each Coordinate is the sum of all the underlying transactions.
Problem Statement
Any proposed solution should be able to address the following 4 main areas:
● It should be able to consume the data from streaming systems like Kafka in real time with millisecond or very low second latencies. It should also process the data in batches.
● Users should be able to query data with millisecond to very low second latencies.
● The database should be able to scale up to 100’s of concurrent queries.
● The users should be able to do analytics on the source data.

Why not databases like RedShift?
● Can not stream huge amounts of data.
● Does not give millisecond response times.
● Does not provide high concurrency.
● Managed service might cost more.
Why not NoSQL (e.g.. Cassandra, Dynamo, HBase, MongoDB/Couchbase)
● NOSQL databases like Cassandra and HBase scales with Real-time streaming. Mongo/Couchbase will not scale for real time streaming of that volume.
● Provides Millisecond response times for querying data on partition keys only.
● Provides High Concurrency.
● Does not support analytics.
● Does not support OLAP.
Unified Lambda Architecture
This blog proposes Unified Analytical solution (Realtime DW + OLAP) that addresses the following:
● Real Time data streaming
● Real Time Analytics
● High Concurrency
● OLAP Analytics
● High Availability
● Cost effective.
The proposed solution will solve the current use cases and provide a very good enterprise solution and add a lot of value to the data like providing more real-time reporting, analytics, training models on real time data and also on large volume of data.

The above diagram explains how the proposed solution will work. It uses “unified lambda architecture” which provides Batch, Stream, and Speed layers together. The data ingested into detailed tables and Rollups/Cubes will be synced behind the scenes based on the design and instructions provided.
When users try to access data, the query optimizer redirects to underlying data (can be detailed, aggregated and both) based on the query need. End users need not know the underlying mechanism and they just simply use SQL to access the data.
Technologies
● Apache Druid
● Apache Starrocks
● Apache Kylin
The following table compares the features for each technology mentioned above:
| Item | Druid | Kylin | Starrocks |
|---|---|---|---|
| Type | Time Series with good OLAP support | Pure OLAP (MOLAP) (Uses mdx cubes) | Real-time Data warehouse with OLAP (uses materializers) |
| Concurrency/Throughput | High | Very high | Very high |
| Storage | Columnar/Parquet | HBase/Parquet | Columnar/Parquet |
| Indexing | Time is always primary partition | All dimensions are equally partitioned/indexed. | Primary, bitmap, bloom filter. |
| Updates/Deletes | Does not support | Does not support | Supports updates/deletes provided tables created with proper schema. |
| OLAP | Some rollups, mainly time based. | Full OLAP (MOLAP) | Uses aggregate and materialized views. Supports MOLAP/HOLAP/ROLAP |
| Real-time ingestion | Scales to 100s of millions per hour. | Scales to 100s of millions per hour. | Scales to 100s of millions per hour |
| Analytics | Supports aggregates, slice, and dice of the data. | Very faster analytics compared to any other databases because it stores data in MOLAP format and pre-aggregates all possible permutation and combinations of all the dimensions | Can create all possible aggregation and can be predefined what aggregations we need for faster analytics. |
| Star Schema/Data Warehouse | Supports through in-built lookups. Or need to follow a mixed approach. Fact table will be in Druid and Dimension lookups can be in some other database like Redis. | Supports Star schema while processing. But dimension metadata needs to be either cached or stored somewhere like Redis for faster access. | Support full star schema and even snowflakes. |
| Window functions/complex SQL | Does not support | To good extent | Fully supported |
| Table joins | Support to certain extent but its use is not recommended | Support to certain extent but its use is not recommended | Fully supported. |
| Hive Tables/external tables | Not supported | Not supported | Supported. Also supports mySql tables. |
| Connectivity | HTTP and its own connectors | HTTP and its own connectors | Uses MySQL client connectors and MySQL JDBC, so it supports wherever MySQL can connect. |
| Maintenance | Moderate | High | Low to Moderate |
| Vendor support | Imply | Kyligence | Starrocks |
Cube Vs Materializers
An OLAP cube is a data structure that overcomes the limitations of relational databases by providing rapid analysis of data. Cubes can display and sum large amounts of data while also providing users with searchable access to any data points. This way, the data can be rolled up, sliced, and diced as needed to handle the widest variety of questions that are relevant to a user's area of interest.
Processing of an OLAP cube occurs when all the aggregations for the cube are calculated and the cube is loaded with these aggregations and data. Dimension and fact tables are read, and the data is calculated and loaded into the cube. When we design an OLAP cube, processing must be carefully considered because of the potentially significant effect that processing might have in a production environment where millions of records may exist. A full process is very compute intensive and takes a very long time based on the amount of data and computation we are using.
Adding more dimensions adds more complexity to cube processing. When real-time data comes in, it might take some time to add it to all partitions.
The amount of cube processing can be reduced by optimizing it based on query usage and/or space-based optimization.
On the other hand, Materializers are a small subset of the Cube which will reduce time and complexity of cube processing.
"About Author"